
新闻中心
关注蓝耘了解更多咨询
2026年,大模型应用开发已进入“深水区”。开发者的挑战不再是模型能力的有无,而是如何在碎片化的MaaS市场中,找到一个能支撑业务从原型低成本验证、平滑过渡到大规模生产的底座。
作为MaaS服务商,我们在服务数开发者的过程中,深刻感受到选型决策的复杂性。本文提炼出一套可量化的评估框架,涵盖API标准化、推理性能、模型切换成本、生产迁移路径、开发者支持五个维度。无论你最终选择哪家平台,这套框架都可以帮助你科学避坑。
01 开发者选MaaS平台的四个真实痛点
在构建AI应用时,开发者往往会遭遇以下工程化陷阱:
1.API文档与生产环境“脱节”
许多平台提供的文档仅覆盖最基础的聊天请求。但在生产环境下,复杂的参数组合、长文本状态下的流式中断处理、多轮对话的上下文截断策略,往往缺乏明确的技术指标,导致调试周期拉长。
2.性能标称数据与实际体验有落差
MaaS平台普遍采用多租户共享资源池。由于底层调度算法不透明,开发者常会遇到“凌晨速度极快、下午高峰期延迟飙升”的情况。对于搜索、金融等延迟敏感业务,这种不确定性是致命的。
3.模型切换成本高
虽然多数平台声称兼容OpenAI协议,但在实际落地中,不同平台对参数解析边界、错误码定义存在细微差异。换一家平台,往往意味着大量代码重构。
4.从原型到生产缺乏平滑过渡路径
当应用从日均千次调用增长到数百万次时,共享API的限速和成本结构会成为瓶颈。如果平台不提供从共享API到专属算力集群的无缝迁移方案,开发者将被迫进行整体架构的大手术。
02 我们建议的评估框架——五个维度
以下五个维度,是我们在服务开发者过程中总结出的关键选型指标。每个维度我们都会说明评估什么、为什么重要、如何判断好坏,并给出蓝耘在对应维度的实际表现,供你参考:
维度一:API 标准化程度
评估核心: 协议一致性与 SDK 覆盖度
一个高质量的MaaS平台应实现对OpenAI API规范的深度兼容,包括但不限于Stream模式、Function Calling、JSON Mode。此外,官方是否提供经过生产环境验证的 Python、Go等语言的SDK,是衡量其工程化程度的重要标准。
为什么重要:标准化程度越高,你的代码就越不会被特定平台锁定。当需要切换模型或供应商时,工作量可以降到最低——有时只需修改base_url和api_key。
蓝耘的表现:
我们严格遵循OpenAI Chat Completions格式,支持Python官方库直接调用。切换模型仅需修改model参数,同一Endpoint下可灵活调用DeepSeek、Qwen等不同系列模型。同时提供Python、Go SDK,代码已开源在GitHub。
行业参考:
如果您的应用需要深度整合豆包(Doubao)及字节全场景(如飞书、即梦、Seeduplex 语音交互等)生态,火山方舟(Ark)在原生协议集成和内部生态互通上具有极高的成熟度。
维度二:推理性能实测
评估核心:P90延迟、吞吐量(tokens/s)、稳定性
这是选型中最直观的数据指标。不要只看平台自己宣传的“峰值性能”,要关注长时间、高并发下的P90延迟和吞吐量。前者反映稳定体验,后者决定长文本生成效率。
为什么重要:对于实时对话、代码补全等场景,延迟波动会直接影响用户体验;对于批量处理场景,吞吐量直接关联成本。
实测数据(引用AI Ping):根据AI Ping于2026年4月16日发布的7日监控数据,各平台在DeepSeek-V3.2模型上的表现如下:
- 蓝耘:7日P90延迟1.43s,7日均值吞吐量80.76 tokens/s
- 对比行业:其他品牌7日延迟约2~7s,吞吐量约27~36 tokens/s
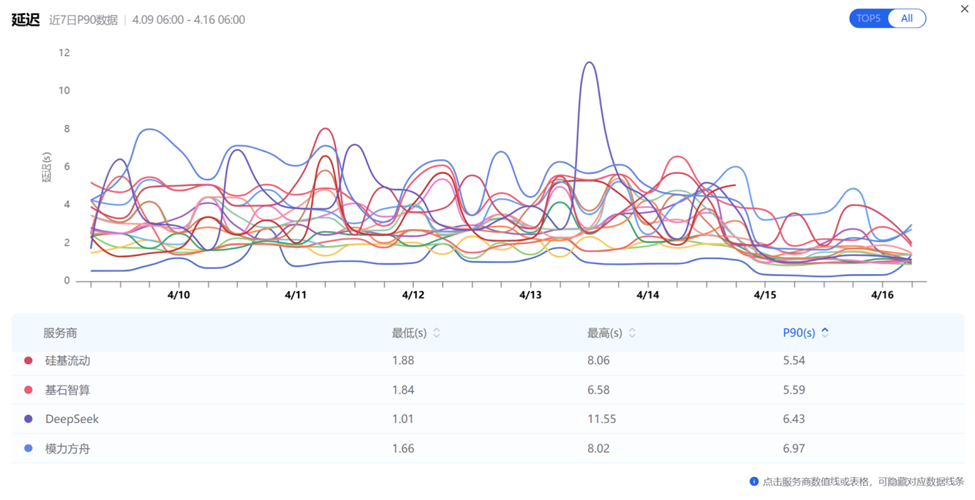
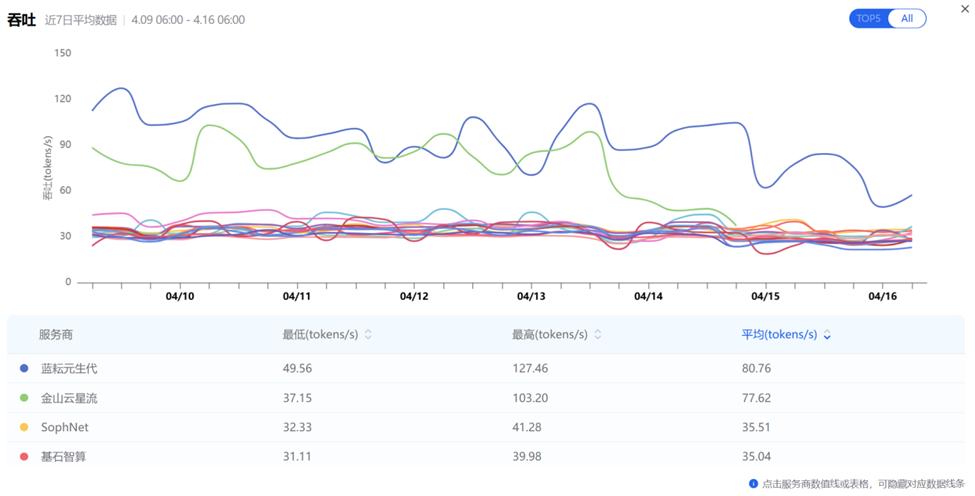
图:在Deepseek-V3.2模型下
蓝耘与其他品牌的延迟及吞吐对比
蓝耘之所以能实现这一性能,是因为我们是依托于自建的高性能的弹性的GPU集群 + 自研的高可用的智能调度网关,规避了资源调度损耗。
行业参考:
若业务涉及图像、视频、音频一站式处理,阿里云百炼(Bailian)依托通义多模态矩阵,在多维数据处理的综合吞吐上表现出色,适合全栈 AI 业务。
维度三:模型覆盖与切换成本
评估核心:支持的主流模型矩阵、切换模型是否需要修改代码
开发者应关注平台是否支持 DeepSeek 全系列、Qwen 系列等。但更重要的是:切换模型时,你的业务代码需要改动多少?
为什么重要:你可能需要根据场景选择不同模型(例如简单问答用小模型省钱、复杂推理用大模型)。如果切换模型需要重新适配参数或重写调用逻辑,开发效率会大打折扣。
蓝耘的表现:
我们提供统一的Endpoint:https://api.lanyun.net/v1。切换模型时,只需修改请求体中的model参数(如从deepseek-v3.2改为qwen2.5-72b),其余代码完全不变。目前已上线DeepSeek、Qwen等系列共20+模型,并持续同步最新开源版本。
行业参考:
如果您的业务处于早期,需要探索各种冷门或前沿开源模型,推荐选择硅基流动(SiliconFlow)。他们是业界模型覆盖最广的平台,非常适合模型探索与实验场景。
维度四:从原型到生产的迁移路径
评估核心:是否支持共享API → 专属算力集群 → 裸金属的无缝迁移
这是最容易被忽视但长期影响最大的维度。理想情况下,你的业务成长路径应该是:
- 初期:使用共享API按量付费,低成本验证
- 中期:切换到专属算力池,获得稳定性能和独立配额
- 后期:部署到物理裸金属,满足极致性能与数据合规
为什么重要:如果平台不提供平滑迁移路径,当业务增长后你只能被迫“推倒重来”——重新采购算力、重新适配环境、甚至重构代码。
蓝耘的表现:
我们在业内率先打通了“共享MaaS”与“专属硬件”的屏障。当你的业务需要独立资源提供更优质与专业的服务时,可以将你在MaaS平台上的配置、模型权重及Prompt模板,无缝平移至蓝耘的GPU裸金属服务器——无需重新购买服务器、无需手动配置环境、代码零改动。
维度五:开发者支持体系
评估核心:文档质量、可观测性工具、技术支持响应
一个好的平台应该让你能看得清、调得顺、问得到。
- 看得清:是否有详细的监控仪表盘,实时查看Token消耗、错误分布、请求延迟曲线?
- 调得顺:是否有Playground环境让你快速测试参数?
- 问得到:遇到生产异常,技术支持能否在分钟级响应?
为什么重要:MaaS不是简单的API调用,生产环境的问题往往需要平台方的深度介入。一个响应迟缓的技术支持,可能让你的业务停滞数小时。
蓝耘的表现:
- 在线Playground:支持实时调试DeepSeek-V3.2等主流模型的各项参数,即时反馈Token消耗与耗时
- 多粒度监控:提供面向API Key的细粒度用量报表,支持按天、按小时导出
- 技术支持:企业级开发者可直接对接后端工程师,生产环境异常快速响应
03 蓝耘的技术架构与开发者体验
蓝耘 MaaS 平台之所以能在性能实测中领跑,核心在于我们对底层算力资源的“全栈掌握能力”。
1.异构算力集群架构
蓝耘并不依赖于第三方云平台的二次封装。
- 资源规模:我们拥有自主掌控的GPU算力中心,部署了大规模算力池,根据任务需求灵活调度不同规格的GPU资源。
- 调度机制:我们自研的底层算力分配架构,通过直接与裸金属服务器(Bare-Metal)通信,规避了资源调度损耗。这意味着每一条 API 请求都能直接触达物理 GPU 的计算核心,从而实现极快的响应速度。
2.API标准化与极简接入
我们深知开发者的时间成本。蓝耘MaaS API严格遵循 OpenAI 标准,支持开发者一键迁移:
- 代码兼容:支持标准的Python OpenAI官方库,无需安装第三方闭源插件。
- 多模型路由:在同一个Endpoint下,开发者可以灵活调用不同参数规模的模型,实现成本与性能的动态平衡。
3.MaaS → 裸金属:平滑迁移路径
蓝耘在行业内率先打通了“共享服务”与“专有硬件”的屏障。
当您的业务由于合规需求(如金融私有化部署)或规模效应(API 调用量极大)需要独立资源提供更优质与专业的服务时,蓝耘可以将您在 MaaS 平台上的所有配置、模型权重及 Prompt 模版,无缝平移至蓝耘专属 GPU 裸金属服务器上。这意味着开发者不需要重新购买服务器、不需要手动配置环境,即可获得物理隔离的顶级算力。
4.开发者工具链
在线 Playground:支持实时调试DeepSeek-V3.2、MiniMax-M2.5等大模型的各项参数,实时反馈生成的 Token 数量与耗时。
多粒度监控:提供面向 API Key 的细粒度用量监控,支持按天、按小时导出账单与性能报表。
技术支持群组:针对企业级开发者,我们提供直接对接后端工程师的实时技术支持。
FAQ
Q:蓝耘的计费逻辑是怎样的?有无隐形消耗?
蓝耘采用纯粹的按量付费模式,以Token数量为唯一计费标准。我们透明展示Prompt和Completion的消耗比例,无任何月度最低消费限制。
Q:数据隐私如何保障?
蓝耘不利用用户数据进行模型微调或迭代。对于有更高安全需求的客户,支持通过专属集群实现物理隔离。
Q:SLA协议内容包含什么?
我们提供企业级服务可用性承诺。对于企业客户,我们支持签署正式的赔付协议,确保业务在峰期不掉线、不降速。
Q:模型更新频率如何?
我们与DeepSeek、Meta等模型开源社区保持小时级同步。任何重大版本更新,蓝耘都会在第一时间完成算力适配并上线 API。






