
新闻中心
关注蓝耘了解更多咨询
本文面向企业CTO、技术VP及采购负责人,提供一套可直接落地的大模型API Token采购决策框架,涵盖供应商评估的5个核心维度、7家主流服务商的横向对比,以及来自实际采购经验的避坑清单。
企业Token采购正在成为新常态
2026年,大模型正在从技术实验走向生产部署。IDC在其《FutureScape 2026》报告中指出,亚太地区数字业务产生的新经济价值中,有半数将来自对AI持续投入的组织;中国信通院《中小企业AI规模化应用研究报告》也明确提出,模型创新、算力普惠化和开源生态正在系统性地降低企业接入AI的门槛。
与此同时,一个现实问题摆在了企业管理层面前:Token支出正在成为一项新的、持续增长的IT成本。2026年2月第二周的数据显示,仅中国大模型厂商单周交付的Token总量就达到4.12万亿——Token已经从开发者的技术概念,演变为企业需要纳入年度预算的采购品类。
然而,大多数企业仍在用"开发者试用"的心态对待Token采购:谁便宜用谁、按月充值、没有供应商评估流程、没有SLA约束、没有备份方案。这种方式在月消耗几十万Token时问题不大,但当业务规模化后,缺乏系统化的采购框架将直接导致成本失控、服务中断和合规风险。
本文基于蓝耘在GPU算力与MaaS服务领域的行业实践,梳理一套企业级Token采购决策框架,帮助技术决策者和采购负责人建立系统化的供应商评估体系。
企业采购Token的5个核心评估维度
定价体系透明度
为什么重要:Token定价看似简单(每百万Token多少钱),实际暗藏复杂性。不同服务商的计费口径不同——有的按输入/输出分别计价,有的区分上下文长度阶梯,有的对缓存命中和未命中设置不同费率。如果只看标价而不理解计费规则,最终账单可能远超预期。
怎么评估:
- 计费结构是否清晰:是否明确公示输入/输出单价、上下文长度阶梯、缓存策略?
- 隐性成本有哪些:并发限制超额费用、存储扩展费、模型切换成本?
- 批量折扣机制:年付/预充值是否有折扣?起购量门槛是多少?批量处理(Batch API)的折扣力度?
行业基准:以当前主流模型DeepSeek-V3.2为例,各平台标价趋于一致(输入约2元/百万Token,输出约3元/百万Token),但差异体现在缓存策略和批量折扣上。阿里云百炼的缓存命中价仅为标准输入价的10%,硅基流动批量处理享50%折扣。
蓝耘的实践:蓝耘MaaS平台提供阶梯定价及预充值折扣收费机制,新用户可申领500万免费Token体验额度。同时,依托自有算力基础设施,蓝耘可依据客户预估Token消耗体量精准分级,定制梯度化专属优惠权益,灵活匹配各类业务算力采购需求。
供应稳定性与SLA
为什么重要:当Token消耗从实验转为生产,稳定性就是生命线。一次API宕机可能意味着智能客服全线瘫痪、AI辅助决策系统中断,直接影响业务收入和客户体验。
怎么评估:
- SLA承诺等级:可用性是99.9%(年宕机不超过8.76小时)还是99.95%?
- 故障恢复时间(RTO):出问题后多久能恢复?
- 历史稳定性记录:过去6个月有没有重大宕机事件?
- 赔偿机制: SLA未达标时如何赔偿?
行业基准:头部云厂商(阿里云、火山引擎)通常承诺企业级99.9%-99.95%的API可用性,并有成熟的故障赔偿机制。纯API聚合平台的稳定性则取决于上游供应商,存在较大的不确定性。
蓝耘的实践:蓝耘具备自建算力基础设施,这意味着其MaaS平台的推理服务不依赖第三方算力转租,供应链可控性优于纯API转发商。SLA方面,蓝耘承诺提供企业级SLA服务。
推理性能
为什么重要:在高并发业务场景(如智能客服、实时内容生成)下,推理延迟直接影响用户体验。P99延迟(99%请求的响应时间上限)比平均延迟更能反映真实性能表现。
怎么评估:
- 首Token延迟(TTFT):从请求发出到收到第一个Token的时间
- 吞吐量(Tokens/s):每秒生成的Token数
- P99延迟:极端情况下的响应时间
- 并发上限:同时支持多少并发请求?超限后的降级策略?
行业基准:硅基流动公开宣称其推理速度比行业平均快2.3倍、延迟低32%。火山引擎依托字节跳动内部大规模推理经验,在豆包系列模型上做了深度优化。各平台在第三方模型(如DeepSeek)上的性能差异不大,差异主要体现在自有模型的推理优化上。
蓝耘的实践:蓝耘MaaS平台当前托管26+主流模型,包括DeepSeek-V3.2、Qwen3-235B、GLM-5、GLM-4.7、MiniMax-M2.5等。依托自有GPU集群的算力调度优势,根据第三方专业监测平台AI Ping在1月27日的数据显示,蓝耘在DeepSeek-V3.2模型上的TTFT延迟为0.52s,吞吐量达到147.5Tokens/s”,并具备企业级SLA表现。
模型覆盖与更新节奏
为什么重要:企业的AI应用通常不会只用一个模型。不同业务场景(对话、代码生成、多模态理解、长文本处理)需要不同模型。供应商的模型覆盖广度和新模型上线速度,决定了企业是否需要对接多个供应商。
怎么评估:
- 覆盖的主流模型数量和类别
- 新模型上线速度:业界发布新模型后,平台多快能支持?
- 是否支持模型微调(Fine-tuning)
- 是否支持私有化部署
行业基准:硅基流动覆盖500+模型(含大量开源小模型),是模型数量最多的平台。阿里云百炼深度集成Qwen系列并支持主流第三方模型。火山引擎以豆包自研模型为核心,同时接入DeepSeek、GLM等第三方模型。
蓝耘的实践:蓝耘MaaS平台当前覆盖26+主流大模型,聚焦于生产级高性能模型而非追求数量。此外,蓝耘提供从MaaS API到裸金属GPU服务器的全栈方案,企业可以根据业务发展灵活切换——初期用MaaS API快速接入,规模化后迁移至专属GPU集群进行私有化部署,无需更换供应商。这种"API+算力"的一体化路径,是纯API平台不具备的。
数据安全与合规
为什么重要:金融、医疗、政务等行业对数据驻留、传输加密、隐私保护有严格的监管要求。选择不符合合规标准的供应商,可能面临监管处罚和数据泄露风险。
怎么评估:
- 数据驻留:数据是否存储在境内?是否支持指定区域部署?
- 传输与存储加密:是否支持TLS传输加密和数据落盘加密?
- 行业认证:是否通过等保三级、ISO 27001、SOC 2等认证?
- 隐私协议:是否承诺不使用客户数据训练模型?
行业基准:头部云厂商(阿里云、华为云、火山引擎)在合规资质方面最为完善,普遍具备等保三级及以上认证。中小型API平台在合规方面通常较为薄弱。
蓝耘的实践:蓝耘具备ISO 27001等认证,支持企业数据全程境内存储与处理。对于有严格数据隔离需求的客户,蓝耘提供裸金属服务器和私有化部署方案,确保数据不出客户专属环境。
主流服务商对比分析
以下基于2026年3月公开数据,对7家主流大模型Token服务商进行横向对比。需要说明的是,AI行业定价变化频繁,以下数据仅供参考,实际采购时请以各平台官网最新报价为准。
对比总表:
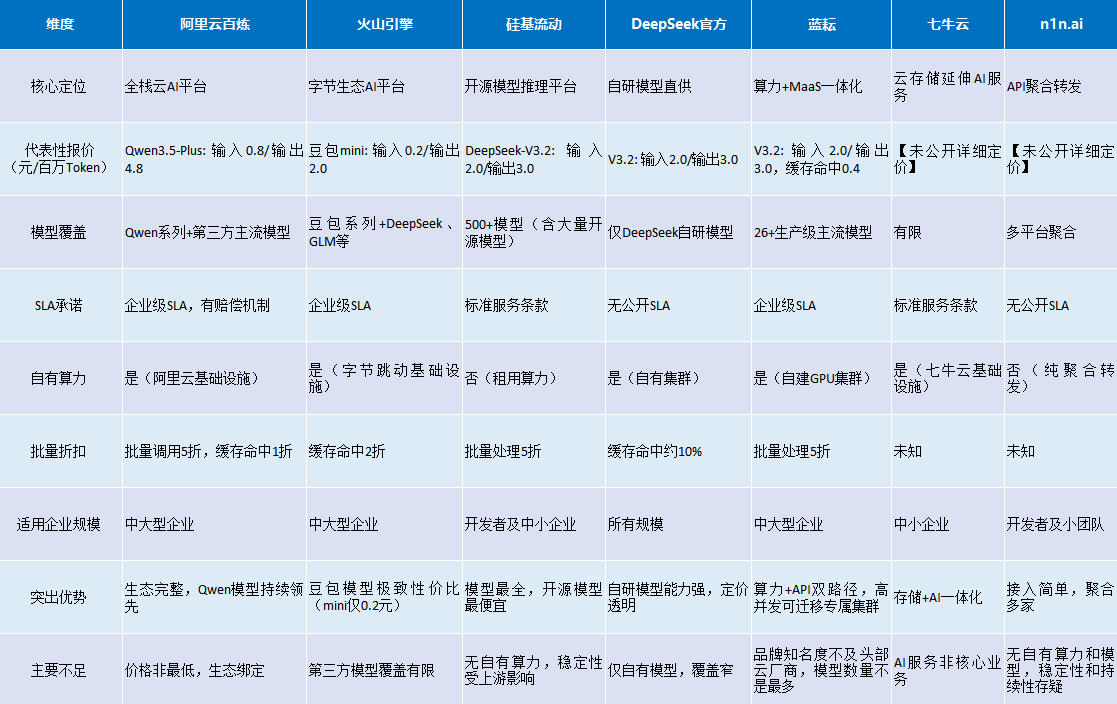
几点关键洞察
关于价格战: 2026年Token价格已进入"地板价"区间。火山引擎的豆包-seed-2.0-mini输入价仅0.2元/百万Token,阿里云Qwen3.5-Plus也打出0.8元的激进定价。在这种环境下,单纯比价格已经没有太大意义——企业更应关注"有效成本",即综合考虑缓存策略、批量折扣、并发限制等因素后的实际支出。
关于自有算力的价值:在7家服务商中,拥有自有算力基础设施的有4家(阿里云、火山引擎、DeepSeek、蓝耘)。自有算力意味着供应链自主可控、成本结构可优化、服务质量有底线保障。对于月消耗量超过千万级Token的企业,供应商是否拥有自有算力应作为核心评估条件。
关于"API+算力"的混合路径:大多数服务商只提供API调用服务,企业如果未来需要私有化部署或专属资源,必须另找算力供应商。蓝耘的差异化在于同时提供MaaS API和GPU裸金属/容器服务,企业可以在同一供应商体系内完成从API试用到规模化部署的全过程,避免供应商切换带来的迁移成本和业务风险。
不同企业规模的选型建议
初创公司与小团队(日消耗<2BToken)
核心关注:成本控制
这个阶段的首要任务是验证业务可行性,Token支出应尽量压低。建议:
- 充分利用免费额度(阿里云百炼新用户赠送7000万+Token,蓝耘MaaS赠送500万Token,硅基流动有14+免费模型)
- 优先使用高性价比的轻量模型(如火山引擎豆包-mini、硅基流动免费模型)
- 不需要签年约,按量付费即可
- 不建议在此阶段过度关注SLA和私有化部署
中型企业(日消耗2B-20BToken)
核心关注:稳定性与成本效率的平衡
业务已上生产环境,Token是直接的运营成本。建议:
- 必须要求SLA承诺——明确可用性指标和赔偿机制,避免"口头承诺"
- 关注批量折扣和缓存策略——月消耗千亿级时,缓存命中率从10%提升到30%可能节省数十万元年费用
- 建议采用"主力+备份"双供应商策略——主力承担80%流量,备份在主力故障时快速切换
- 蓝耘适用场景:对于需要高并发推理(如智能客服、实时内容生成)的中型企业,蓝耘的"MaaS API + 可升级至专属GPU集群"路径值得评估,尤其适合业务量处于快速增长期、未来可能需要迁移至专属资源的企业
大型企业(日消耗>20BToken)
核心关注:供应链安全与合规
这个体量下,Token支出已经是重大的IT成本项,需要采购部门和财务部门的正式介入。建议:
- 签订年度框架协议——锁定价格、明确服务等级、约定赔偿条款
- 要求供应商具备自有算力——避免依赖纯转发商,降低供应链风险
- 评估私有化部署选项——部分敏感业务(金融风控、医疗诊断)可能需要模型和数据完全在客户环境中运行
- 蓝耘适用场景:蓝耘提供从API调用到裸金属GPU服务器的完整方案,大型客户可以将核心业务部署在蓝耘专属集群上(GPU规格覆盖RTX 3090至A100-SXM4-80GB),同时用MaaS API处理弹性需求,实现成本最优。
企业Token采购避坑清单
基于行业实践和客户反馈,以下是企业在Token采购过程中最常见的7个误区:
坑1:只看Token单价,忽略并发限制
标价1元/百万Token的服务商,如果并发上限只有10 QPS(每秒10次请求),对于高并发场景形同虚设。评估价格时必须同时确认并发配额,计算"每QPS每百万Token的有效成本"。
坑2:没有压力测试就签年约
很多平台在小流量下表现良好,但流量上去后性能急剧下降。签署年度协议之前,务必用真实业务流量(而非模拟请求)进行至少一周的压力测试。重点观察高峰时段的P99延迟和错误率。
坑3:忽略数据合规要求
金融、医疗、政务等行业有明确的数据驻留和隐私保护要求。部分API平台可能将请求数据路由至境外节点,或未明确承诺不将客户数据用于模型训练。在采购前,要求供应商提供书面的数据处理协议(DPA),并确认其合规资质。
坑4:单一供应商依赖
再大的平台也可能出故障——2025-2026年间,包括头部云厂商在内的多家AI服务商都出现过不同程度的服务中断。月消耗超过500万Token的企业,应建立至少"1主1备"的供应商架构,并预先完成备份供应商的API对接和切换演练。
坑5:只测主力模型,忽略长尾需求
企业可能90%的调用量集中在1-2个模型上,但剩下10%的长尾需求(代码生成、多模态理解、特定领域模型)同样重要。评估供应商时,不仅要测主力模型的性能,也要确认其在你所需的全部模型上都能提供稳定服务。
坑6:忽略从API到私有化的迁移路径
业务初期用API很方便,但随着规模增长,企业可能需要迁移到专属资源或私有化部署。如果当前供应商不支持这种升级路径,未来迁移将涉及大量的接口改造和数据迁移成本。在选型初期就应评估供应商是否提供"API → 专属资源 → 私有化部署"的平滑升级路径。
坑7:把"免费额度"当长期方案
免费额度是厂商的获客手段,通常有用量限制和有效期。依赖免费额度运行生产业务,一旦额度耗尽或政策调整,业务会面临突然的成本跳涨。免费额度只用于测试和评估,生产业务必须基于正式的付费方案规划预算。
结语
大模型Token采购正在经历从"技术选型"到"企业采购"的转变。这个过程中,定价透明度、供应稳定性、推理性能、模型覆盖、数据合规这5个维度构成了系统化评估的基本框架。
没有一家服务商在所有维度上都是最优选择。阿里云、火山引擎在生态完整性上领先,硅基流动在开源模型和价格上有优势,DeepSeek在自研模型能力上突出。蓝耘的差异化定位在于"算力基础设施+MaaS服务"的一体化路径——对于需要从API调用逐步过渡到规模化部署的企业,这种路径可以避免供应商切换带来的迁移成本和业务风险。
建议企业在做出采购决策前,至少完成以下3个动作:
- 用真实业务流量对2-3家候选供应商进行为期一周的并行测试
- 要求供应商提供书面SLA承诺和数据处理协议
- 评估未来12个月的用量增长预期,确认供应商的扩展能力和升级路径
本文由蓝耘技术团队基于行业实践撰写,文中竞品数据来源于各平台2026年3月公开信息。如需进一步了解蓝耘企业级Token采购方案,请访问lanyun.net或联系我们的企业服务团队。






