
新闻中心
关注蓝耘了解更多咨询
当AI大模型从技术Demo走向生产环境,推理性能已不再是单纯的工程指标,而是直接决定用户体验与业务ROI的生命线。在智能客服、代码辅助、长文档分析等高频场景中,每一单位tokens/s的吞吐量跃升,都意味着用户等待时间的锐减;每一毫秒延迟的优化,都直接转化为商业竞争的核心护城河。
而模型推理性能的跃升,绝非单一算法的线性突破,而是贯穿基础硬件、中间件引擎到顶层调度架构的全栈式系统工程。那些在应用实测中持续领跑的MaaS服务,其背后必然是底层技术架构的软硬件协同、推理引擎优化与架构革新的集大成者。
万P级硬核底座,筑牢性能地基
大模型推理性能的上限始于硬件。再精妙的量化算法,也需要坚实的算力底座才能释放潜能。蓝耘在全国部署多个多个AIDC(智算中心)节点,算力规模超过万P级,相当于数万张高性能GPU协同工作,从根本上解决了大模型推理的资源瓶颈。这一架构的核心优势在于“全栈可控”。基于自建数据中心的优势,蓝耘得以在硬件层面实施“量体裁衣”式的专项优化,从新一代AI加速卡的集群调度、内存管理到节点间的无损网络传输,每个环节均针对大模型推理特征进行了深度适配。这种将云计算灵活性与边缘计算低延迟特性相结合的混合架构,为高性能推理筑牢了第一道防线。
推理引擎突围:vLLM与算子级优化的微观革命
在硬件之上,推理引擎是决定性能的“CPU”。当前业界领先的MaaS服务平台,早已摒弃了简单的模型“上架”模式,转而深耕底层加速框架。
蓝耘元生代云MaaS平台底层深度融vLLM高性能推理引擎,通过PagedAttention技术解决KV Cache显存碎片化问题,可将大模型推理吞吐量提升数倍。vLLM的最新V1引擎架构将调度器与执行循环分离,通过缓存请求状态、仅在工作进程间传递差异信息,大幅降低进程间通信开销——这意味着用户无需复杂调参,即可获得“开箱即用”的性能红利。
在更微观的算子层面,蓝耘工程师团队对推理引擎开展多轮迭代优化,所有优化均经数亿次API调用的生产环境验证,真正做到落地可用,即用即优。其核心包括:
- 算子融合与量化加速:将多个连续算子合并为单一内核执行,减少内存读写次数;同时采用 FP8 量化技术,在几乎无损精度的情况下压缩模型体积,加速矩阵运算。
- FlashAttention机制:通过tiling分块计算,将Attention模块的内存访问从HBM(高带宽内存)到 SRAM 的往返次数降至最低,显著降低首Token时延(TTFT),这也是提升长文本首字响应体验的关键。
- KV缓存优化:针对DeepSeek-V3.2等模型的MLA(Multi-Head Latent Attention)架构进行专项适配,通过预混洗KV缓存布局,使内存访问模式与GPU架构深度对齐,解码吞吐量获得显著提升。
架构护航:高可用设计保障极致稳定
真实生产环境的最大考验在于不确定性:GPU故障、突发流量波峰、混合负载交织……当业务流量如潮汐般涨落,静态的集群架构无法承载高可用的需求。
蓝耘自研的智能网关系统,正是为此类动态环境量身打造。它不仅是流量接入与协议转换的入口,更是一个具备业务语义感知能力的智能调度中枢:
- 基于语义的智能路由:实时分析请求特征(如长文本预填、短对话解码),将任务精准分发至云端或边缘节点的最优资源池。
- 动态负载均衡与容错:采用“全局调度+局部加速”协同机制,当监测到某节点故障或过载时,毫秒级完成路径切换与资源扩容,确保 99.95%的高可用性 SLA。
- PD分离架构:将Prefill(预填充)与Decode(解码)阶段拆分至不同节点,既满足首Token低延迟要求,又能通过大容量存储节点支撑超高并发解码,实现吞吐与延迟的精妙平衡。
这种架构设计在电商大促、论文提交高峰等瞬时数十倍流量冲击下优势凸显——千台算力节点全程稳定响应,将推理延迟与错误率控制在极低水平,为客户在高并发推理场景下,提供兼具稳定性与高效性的硬核技术支撑。
批量推理:规模化应用“降本增效”
随着AI与业务系统深度融合,企业正面临海量离线数据处理的常态化挑战。传统实时推理服务在处理这类任务时,往往陷入资源利用率低、单位成本高的结构性困境。
蓝耘元生代云MaaS平台的专属批量推理功能,以“化零为整”的架构破局:将海量碎片化请求整合为规模化作业,通过一站式任务提交、统一调度与集中执行,让算力资源“好钢用在刀刃上”,从根源上简化运维复杂度。
依托自研算力调度引擎,批量推理在性能与成本端实现双重跃升:
- 性能端:大幅优化GPU集群利用率,提升集群吞吐能力。
- 成本端:通过资源复用与任务整合,帮助企业以传统方案50%的成本,释放DeepSeek等先进模型数倍的生产力,为企业规模化AI应用带来确定性的降本增效价值。
实测标杆:从实验室数据到生产级性能
全栈优化的成果,最终需在真实的业务场景中接受检验。在大模型推理服务领域,吞吐量(tokens/s)与响应延迟是衡量平台能力的黄金指标。根据权威AI性能测试平台AI Ping截至2026年1月27日的最新评测,搭载于蓝耘元生代云MaaS平台之上的DeepSeek-V3.2模型,以217.48 tokens/s的吞吐表现和0.38秒的超低延迟登顶榜首,较第二名实现近两倍的性能断层领先,GLM-4.7模型同样以179.44 tokens / 秒的成绩稳居第一。
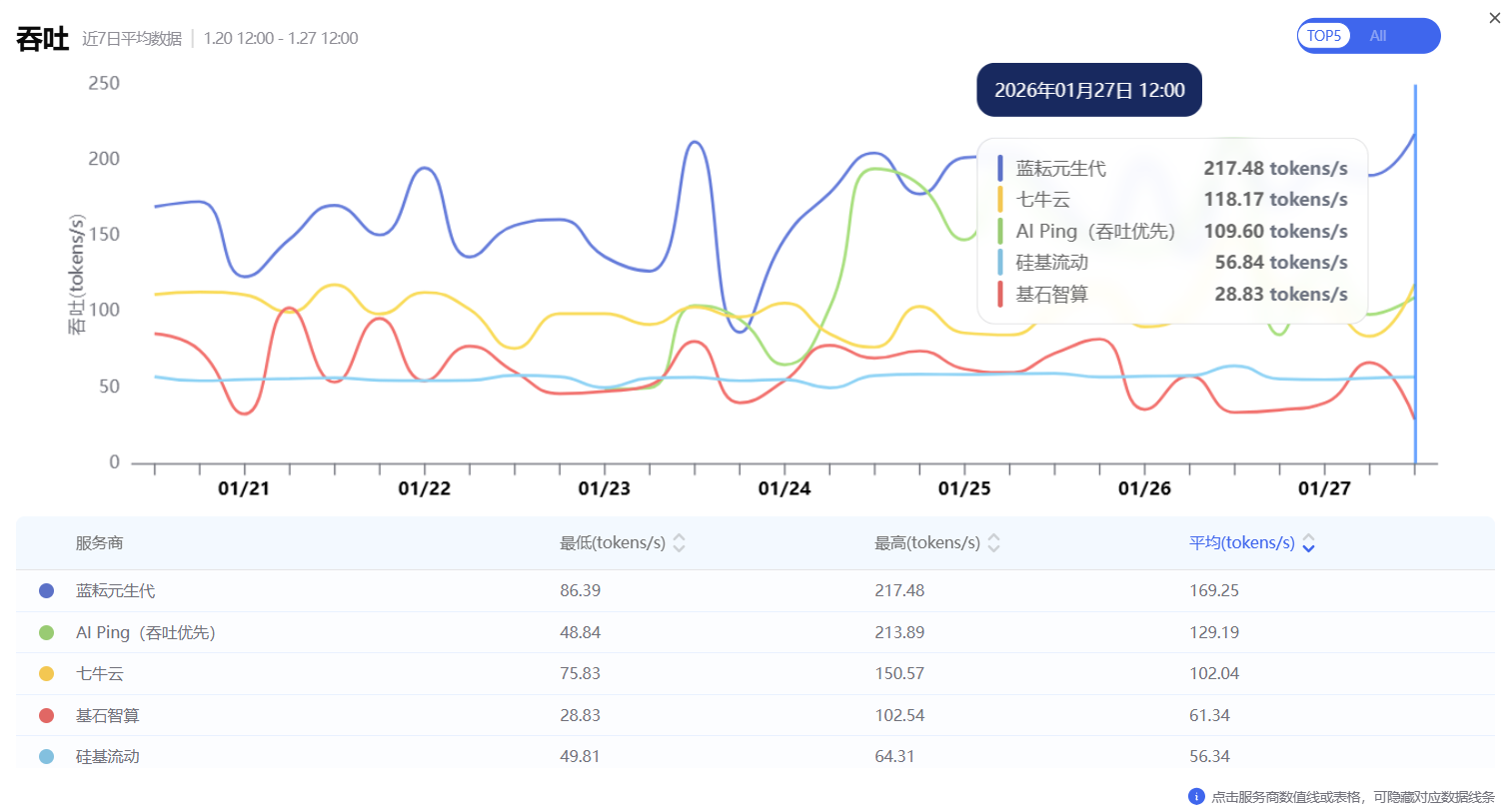
这一系列数据投射到实战场景中,意味着:生成一篇千字深度报告仅需7-10秒,远快于同类平台的15-20秒;支持128K超大上下文规模(特定需求可扩展至200K),可一次性处理10万字合同或完整代码库,长文本分析行云流水。
同时,平台聚合多模态全栈模型生态,支持零代码体验、API快速调用,模型接入极致简化;纯Token计费,成本透明可控——让企业以更低门槛,获取更高效的AI能力。
大模型推理性能的竞争,本质是系统工程能力的较量。从万P算力底座的硬件筑基,到前沿软件调优的微观突破;从规模化推理的效率革新,到智能架构调度的弹性跃升——蓝耘元生代云MaaS平台通过全栈技术优化,将大模型推理性能与服务稳定性推至新高度。这不仅是“让 AI 能力触手可及” 承诺的性能兑现,更诠释了AI应用从“能用”走向“好用”的价值内核。






