
新闻中心
关注蓝耘了解更多咨询
蓝耘元生代上线 MiniMax-M1,超长上下文输入,RL 训练福音
来源: 蓝耘公众号 2025年06月20日
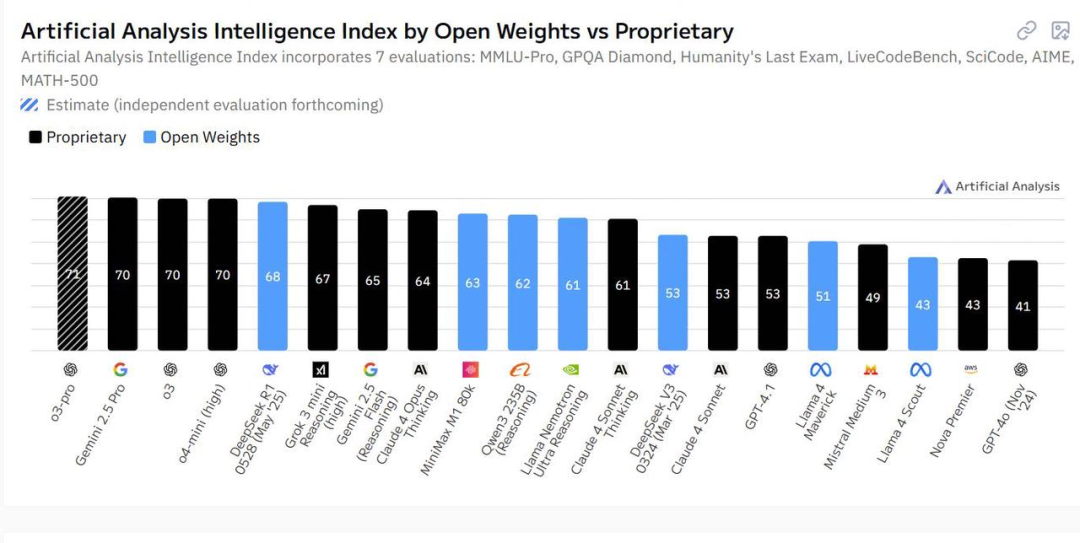
近期,MiniMax发布了全球首个开放权重的大规模混合注意力推理模型—MiniMax-M1。凭借混合门控专家架构(Mixture-of-Experts,MoE)与Lightning Attention 的结合,使其在性能表现和推理效率方面实现了显著突破。
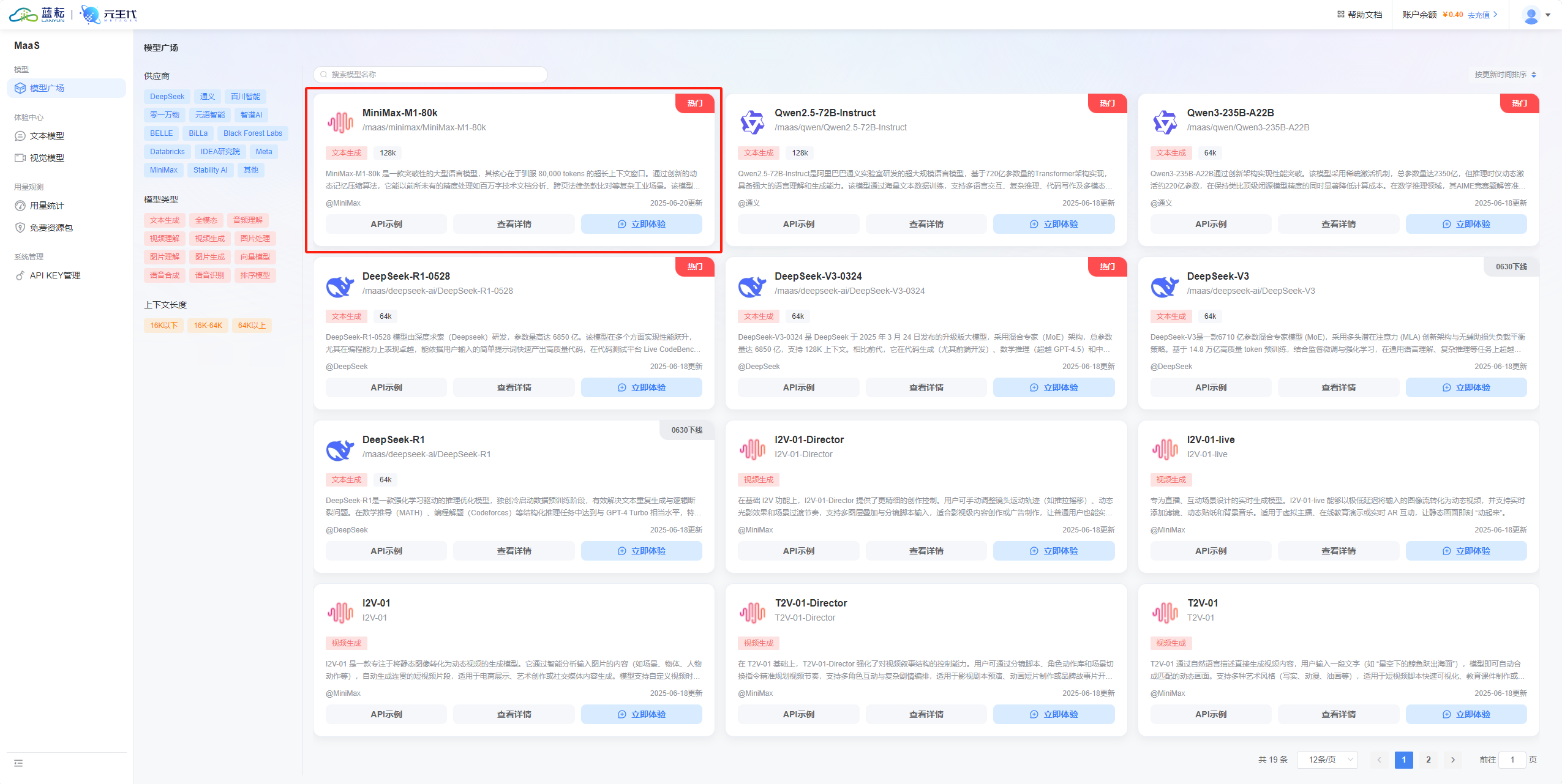
蓝耘元生代模型广场上线了MiniMax-M1-80K版本( 4560 亿参数),注册后赠送100万token(含API调用)。价格为输入 ¥ 1.2 / M Token,输出 ¥ 16 / M Token。
模型特点
通过MiniMax 的各项基准测试数据,与目前已有的大模型相比,展现了三个核心能力——长上下文窗口、RL 训练成本上的优势、Agent 工具调用。具体表现为:
- 支持100万上下文输入,长上下文理解能力是目前包括所有闭源和开源模型在内,能力全球前二的模型
- 支持8万输出token,超过Gemini 2.5 Pro的6.4万,成为目前所有模型最长输出
- 生成10万token时,推理算力只需要DeepSeek R1的25%
- 在智能体工具使用(Agentic Tool Use)维度上的能力比肩DeepSeek-R1、Qwen3-235B
蓝耘元生代MaaS平台,已上线千问系列、DeepSeek系列的量化及蒸馏版本,同时MiniMax的T2V-01系列支持文本、图像、视频等多种模态且全部支持直接调用 API、云端一键部署、私有化部署等多种使用方式,满足不同用户对于数据安全、应用场景的个性化需求。
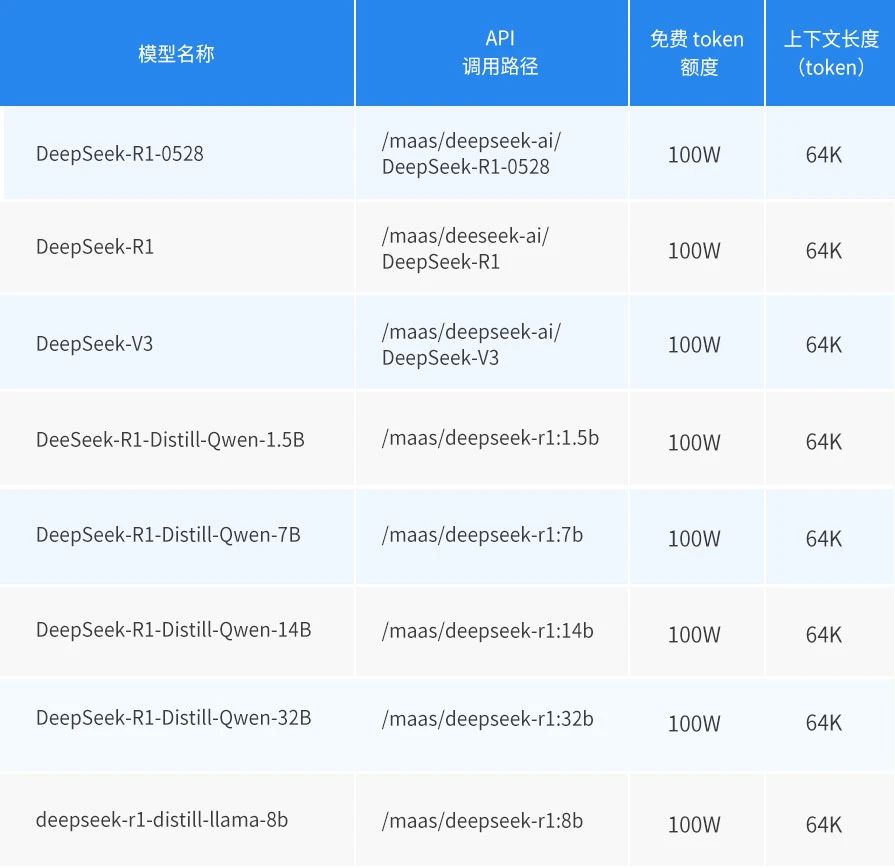
模型体验:https://maas.lanyun.net/api/#/model/modelSquare
API调用文档:https://archive.lanyun.net/maas/doc/






